chapter 1 - reliable, scalable, and maintainable applications
whats-the-point-of-system-design-anyway
chapter 2 - data models & query languages
This chapter covers the three main types of databases and their trade-offs.
chapter 3 - storage and retrieval
This chapter covered various concepts related to storing and retrieving data efficiently, including:
It also covers the differences between OLAP (online analytical processing and OLTP (online transactional processing), and how that affects the ways in which we store data.
OLAP workflows typically retrieve a few columns from many rows in a table (think grabbing the average order price for all payments made through Shopify). Because of this, it can make sense to store data by column on disk, instead of by row. Furthermore, there’s normally many less distinct values in a column than their are rows in a column, meaning compression methods such as run-length encoding (RLE) become viable.
On the other hand, OLTP workflows (typical user behavior) require fast reads and writes to individual rows.
chapter 4 - encoding and evolution
Last chapter focused on how data is stored, and this chapter follows with the format in which this data should be stored.
For this, data needs to be encoded and decoded. See data-encoding.
transfer layer
This chapter also briefly touches on how encoded data is transfered.
database
The application encodes in-memory data to store on the database. In turn, the application decodes data from the database to load into memory.
rest (representational state transfer)
REST is a stateless, resource-based transfer protocol that accepts HTTP requests and returns data in popular formats like JSON and XML.
- The sender encodes their request.
- The server decodes the request.
- The server encodes a response.
- The sender decodes the response.
rpc (remote procedure call)
A call to a function whose implementation is on another node.
Requires an intermediary RPC client that can serve as a middleman to encode/decode requests and responses between the two services (because the two services likely don’t understand each other’s formats).
Because of this, it’s typically used for communication between internal services (like datacenters).
Custom RPC protocols like gRPC use more efficient encodings such as Protocol Buffers.
chapter 5 - replication
This chapter first focuses on the reasoning behind database-replication, and the various strategies that can be used.
Then, in the context of multi-leader and leaderless replication, the author discusses strategies for conflict resolution.
consistency guarantees
When we asynchronously replicate data, we naturally introduce the opportunity for data to become out-of-sync, or inconsistent.
See consistency-patterns.
conflict resolution
When we have concurrent writes to multiple leaders, there is no single consistent ordering of the writes, and so we must perform conflict resolution if we don’t want to end up in an inconsistent state.
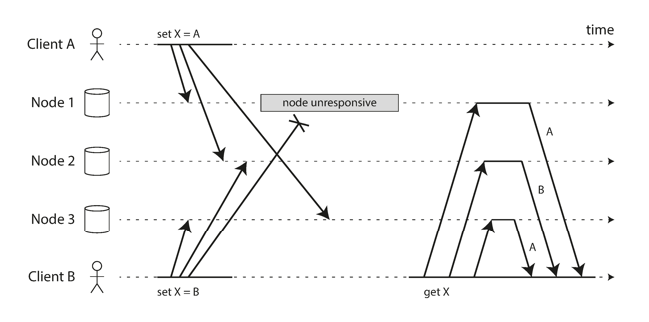
A simple idea is to use the concept of last-write-wins, but then there is a chance that we lose durability as some writes may be silently discarded if a newer write comes in.
Instead, we can realize that we may not need to ensure a complete global ordering, but just that we don’t mess up any causal dependencies. This means that we can achieve causal consistency without needing to ensure that all replicas process writes in the exact same order.
We can achieve this through the versioning of rows/keys in a database, and relying on the application to deal with any conflicting information that it receives.
Warning
Global time is impossible to achieve in a distributed system, as synchronizing multiple clocks is a very difficult problem, and impossible to achieve perfect precision on.
As such, we don’t use timestamps, but use version numbers to propagate logical time instead.
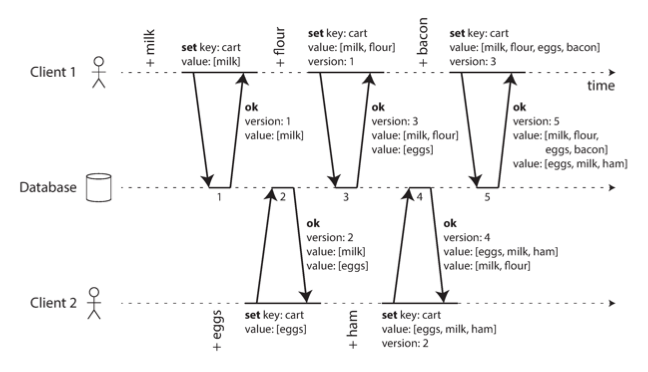
- On a read, the server returns all the not-yet overwritten values for a row/key as well as the latest version number.
- The application performs merge/conflict logic to resolve any varying versions.
- The application submits the merged data with the version number it previously received, and the database can now overwrite all prior versions of the row/key.