Database replication is the practice of keeping copies of the same data on multiple machines.
why do we replicate databases?
There are three primary reasons for replicating databases:
- To increase the availability and reliability of the system. (See Reliability).
- To keep machines geographically close to users and reduce latency.
- To increase read throughput.
replication strategies
replication strategies compared
| Replication strategy | Read performance | Write performance |
|---|---|---|
| Single-leader replication | Fast and scalable in the single datacenter usecase. | |
| Multi-leader replication | ||
| Leaderless replication |
asynchronous vs. synchronous replication
Databases can be replicated either synchronously or asynchronously.
synchronous replication
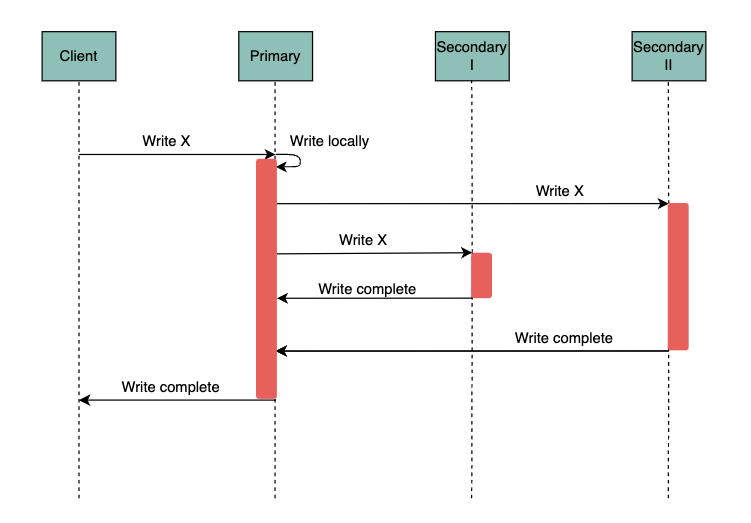
Synchronous replication waits for all followers to update themselves with a write before completing every write operation.
Warning
In practice, synchronous replication is impossible as any follower outage would halt all writes as the leader waits for a response.
Instead, semi-synchronous replication is used instead, in which one follower is synchronized with the leader, whose role can be back-filled by another follower if needed.
pros
- All followers are guaranteed to have up-to-date data, even if the leader fails.
- Reads are fast.
cons
- Writes are significantly slowed down, as all followers must update before the write completes.
- Writes are blocked if any followers are down.
asynchronous replication
Conversely, asynchronous replication writes don’t require any responses from the follower nodes.
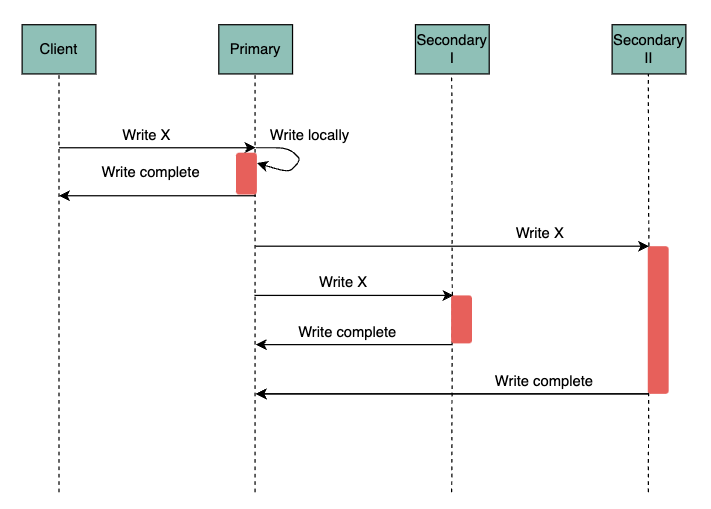
Although this creates a loss of durability as writes aren’t guaranteed to be saved if the leader crashes before propagating the changes to replicas, it is still widely used due to the latency of synchronous replication.
how do we actually replicate data?
It may seem easy to brush off, but replicating data the wrong way can lead to weirdness.
Consider three ways that we can share data to enable replication.
- Statement based replication:
We append all SQL commands (INSERT, UPDATE, DELETE) in a log, and share this log with all followers.
The issue with this method is that many non-deterministic behaviors need to be accounted for, or else they might cause conflicts and inconsistent writes.
Example
- Non-deterministic functions such as
NOW()orRAND()may return different values when run at different times.- Side effects such as triggers and stored procedures may result in different side effects per replica.
- Write-ahead log (WAL) shipping:
The leader shares its write-ahead log with all its followers.
This avoids all of the issues of statement-based replication as the write-ahead log typically stores very specific low-level information about changes to the disk, leaving no room non-determinism.
However, because of this, it’s very difficult to have different nodes running different versions of the database code. This makes it very hard to do rolling upgrades without downtime.
- Logical log (row-based) replication:
The leader stores a log of necessary information to add, delete, and update rows. For example:
- For any created row, the log contains all the information for the row.
- For row deletion, the log contains information necessary to uniquely identify the row.
Tip
This method is very similar to statement-based replication, except that we “bypass” the actual SQL commands and uses the actual values/identifiers to change rows.
comparison of methods
Here’s a comparison of these three methods, in terms of pros and cons.
| Replication method | Pros | Cons |
|---|---|---|
| Statement-based replication |
|
|
| Write-ahead log shipping |
|
|
| Logical log replication |
|
table without id file.inlinks as Backlinks
where file.name = this.file.name