Leaderless replication is characterized by each node in the system being allowed to take reads and writes.
how to propagate writes to all nodes?
Just like with multi-leader-replication, only asynchronous replication makes sense, as using synchronous replication would negate the throughput and availability benefits of leaderless replication.
There are two ways we can propagate writes.
read repair
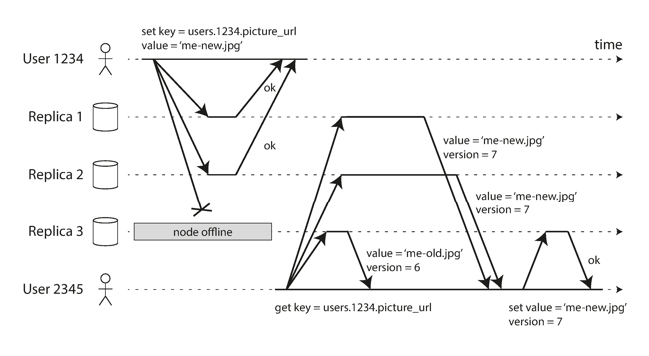
On each read request, the client receives responses from multiple nodes. The client will use the value from the most recent write, but can send write requests to the replicas that returned stale values.
This works best in a system where values are read frequently. However, values can get very out-of-date if they are not read very often.
anti-entropy
A background process runs in your database system, finding mismatched values and updating them. (Kind of like a garbage collector).
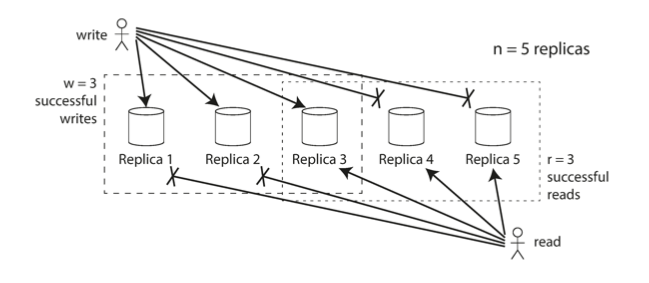
quorum reads and writes
Quorum reads and writes let us guarantee that we receive the latest value from the database without waiting for all nodes. This increases availability.
The basic rule is that for a system with nodes,
where and are the number of responses we require for reads and writes, respectively.
Although this is mathematically solid, there are still some issues that can arise due to asynchronicity. For example:
- If a write and a read happen concurrently, the new write may not have been written to all replicas yet, meaning that the read grabs a set of replicas that haven’t received the new write yet.
- If a node carrying a new value fails and is restored by a node with old value, there could be less than nodes carrying the new value, breaking the quorum.
sloppy quorum
Another issue that can occur with strict quorums is when a network interruption cuts off a client from a large number of its “home nodes” (the nodes that are managing the client’s reads and writes).
In this situation, without intervention, the client would need to wait until the network fault ended. This is why we use sloppy quorums.
We can give up guarantees of consistency for eventual consistency but improve availability if we allow nodes that aren’t normally a part of the home nodes for a user to vote in and accept reads and writes for a client. Eventually, the data will make it back to the home nodes, in a process called hinted handoff.