Also known as master-master replication.
 Multi-leader replication is a method of database-replication that designates
multiple leader nodes that can accept writes from clients.
Multi-leader replication is a method of database-replication that designates
multiple leader nodes that can accept writes from clients.
Tip
Multi-leader replication doesn’t just apply to multiple database leaders.
The concept is the exact same in any applications that allow writes in multiple places. For example:
- Applications that allow changes to be made on separate devices while offline. In these cases, each device functions as a leader node.
- Collaborative editing tools like Google Docs, where each user’s keystrokes are equivalent to writes to a leader node.
why choose multi-leader replication?
There are several reasons to choose multi-leader replication:
- Multiple datacenters
If your application is hosted at multiple datacenters, it is often beneficial to avoid cross-datacenter communication as much as possible, as this traffic goes over less reliable public networks.
By having a leader that can accept writes within every datacenter, the need to cross-datacenter communication is reduced. Furthermore, each users’ data can be assigned a “home” datacenter based on geolocation.
- Increased write throughput
Obviously, with more replicas accepting writes, write throughput can be increased.
replication topologies
With more than two leaders, the way we can connect those leaders increases. This is called a replication topology.
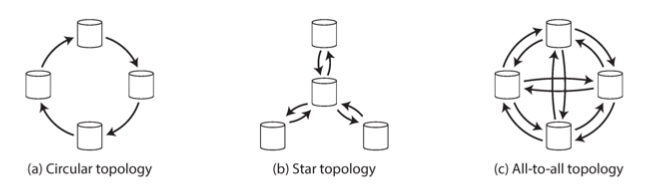
All-to-all is the most common and fault-tolerant approach, but varying network speeds between leader nodes can still cause causal dependency relationships to be broken.
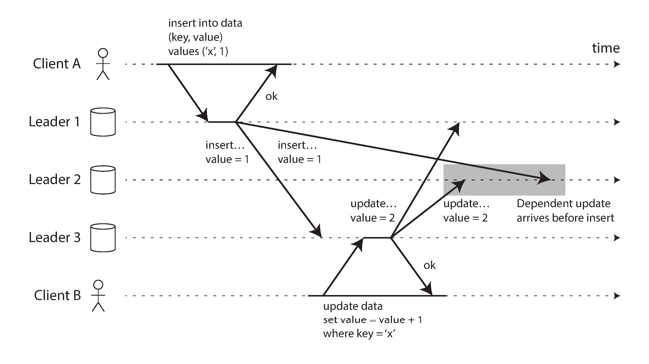
handling conflicts
Naturally, if we begin to allow writes to be made to multiple nodes, we are bound to have writes to the same key with different values, leading to conflicts.
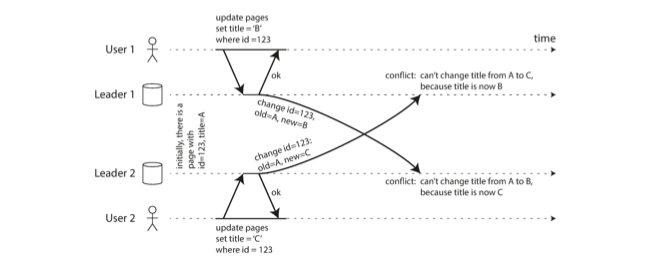
With this in mind, how do we deal with conflicts in these systems?
conflict detection
These conflicts are detected asynchronously, because detecting them synchronously would undermine all the benefits of having multiple leaders.
conflict resolution
There are various strategies to dealing with conflicts in multi-leader setups, although one is specific to multi-leader replication, which is to try to avoid conflicts altogether.
Instead of resolving conflicts, just try to avoid all of them by routing all requests by a user to a single datacenter, so each user has a dedicated leader node.
This solution is nice in theory, but users are bound to switch leader nodes due to downtime or a physical change in location, meaning that conflicts are bound to come up.
For more general write conflict resolution, see conflict resolution