Also known as master-slave replication, active-passive replication.
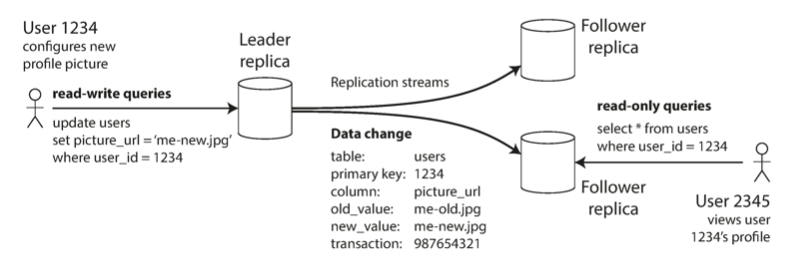
Single-leader replication is a read-scaling architecture in database-replication in which one leader handles all write requests while all followers serve read requests.
when to use single-leader replication
Single-leader replication is most effective in applications where there are significantly more reads than writes.
implementation details
Single-leader replication is implemented with one leader node and any number of follower nodes.
For all writes, a leader processes the write and publishes the change to a replication log, which is sent to followers.
how to add more followers
To add a new follower node to the cluster, we must perform the following steps:
- The new follower database initializes with a recent snapshot of the leader node. These are typically available because snapshots are regularly taken for backup purposes in most database systems.
- The follower connects to the leader and requests all changes on the replication log since the snapshot was taken.
- After processing all of these, the follower is now fully integrated.
how to handle node outages
When considering node outages, we have to consider two cases; when a follower fails, and when a leader fails.
follower failure
Handling follower failure is fairly simple if each follower keeps a log of all the data that it has received from the leader.
After a follower recovers from a failure, it simple requests all of the new changes that it missed while down.
leader failure
Because there is only one leader node in this configuration, a failure of the leader is serious.
We have to appoint a new leader as quickly as possible, in a process called failover.
Read-only mode
As a stopgap during the failover process, the system can run in read-only mode for a short period of time. This at least allows users to continue reading from the database.
The order of events in the case of leader failure goes as follows:
- Determine that the leader has failed.
Nodes in the system will normally send periodic messages to each other to make sure everything is going smoothly, like a heartbeat. If the leader doesn’t respond after a certain amount of time, it can be assumed to be down.
- Choose a new leader.
Typically, the best candidate for a new leader is the follower that has the most up-to-date changes from the leader.
For more details on how a distributed system agrees on a leader, see consensus.
- Appoint the new leader.
Now, we just need to route all write requests to the new leader, and make sure that the old leader is aware that it’s no longer leader once it comes back online.
things that can go wrong
Unfortunately, as single-leader replication is almost always run with asynchronous replication in practice, many complexities arise.
- Missed writes and conflicts.
The old leader may have not shared all of its changes with the new leader before the new leader became leader.
Now, if the new leader begins accepting writes before the old leader comes back online, the change histories diverge, leading to conflicts.
The data written by the old leader is typically just discarded, which can lead to issues, especially if the data is synchronized to external sources.
- Split brain.
The old leader might wake up and think that it’s still the leader, leading to write conflicts.
- Timeout selection.
The selection of a timeout cutoff is difficult.
If the timeout is too long, there may be unnecessary downtime.
If the timeout is too short, more false positives will occur. For example, latency associated with increased load may be mistaken for a leader failure, leading to a positive feedback loop as the failover process places even more strain on the system.