my solution
functional requirements
- A user can retrieve the value for a key, if they have read credentials.
- User can save or update the value of a key that they have the write credentials for.
non-functional requirements
- Value retrieval with a key should be low latency.
- Consistency guarantees.
- Depends on the use case, for sensitive/high-stakes use cases, we’d probably want to guarantee some sort of strong consistency using 2PC (two phase commit).
- For cases where many users are writing keys to the key-value store and most users only care about a few keys, simple causal consistency guarantees like read-your-writes would probably be sufficient.
- We can likely assume that we’ll have many more reads than writes, as the typical use-case for key-value stores is to store values and reference them later with low latency/without recomputing.
- Can confirm with interviewer if this is an acceptable assumption, because there are definitely times when this isn’t the case.
api design
create_or_update(key, value)get_value(key)
design specifics
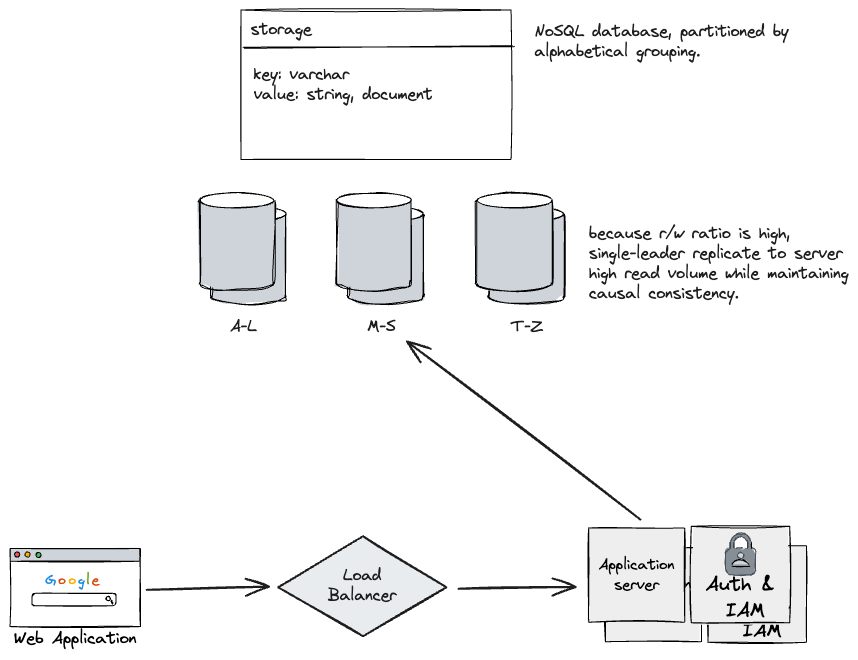
- How do we avoid conflicting keys from concurrent writes?
- Using a single-leader model for each partition, we can use a simple LWW (last-write-wins) heuristic to fail any concurrent request that uses the same key as a previous request.
- Because there is a single-leader, we can maintain total global ordering of requests without sacrificing latency with something like two-phase commit if we had multiple leaders.
- Using a single-leader model for each partition, we can use a simple LWW (last-write-wins) heuristic to fail any concurrent request that uses the same key as a previous request.
- How do we construct keys? Do we just use the ones that the user provides?1
- I think this is fine? We can partition the keys by alphabetical grouping.
- Partitioning details:
- If keys are not distributed evenly by alphabetical order, we could consider hashing to evenly space the values (we could also consider consistent hashing if we need to frequently change the number of active partitions).
positive feedback
- Single leader replication with partitioning was good for a more consistent approach.
- Consistent hashing was a good shout.
critique
meta
-
Should have clarified first if we want to optimize for availabiility or consistency. These two goals lead to different designs.
- An availiability approach likely uses multi-leader-replication or leaderless-replication, ensuring we have higher write and read availability at the expense of consistency.
- A consistency approach would use something less available like single-leader replication, or use slower algorithms like 2PC or quorums to achieve stronger consistency.
-
Could have gone more into detail about low-level components and data flow for
PUT,GET, especially with things like:- Specifics about single-leader replication.
- Dealing with hot nodes, and how to split up existing partitions.
api design
- Didn’t consider breaking up the key-value store by table.
- Didn’t consider other operations like deleting a key, or retrieving a list of keys.
design
- Instead of using LWW, we could utilize a unique monotonic ID to handle conflicts/versioning.
- Missing some sort of high-level service/coordinator that manages partitioning groups, as well as leader assignment/failover.
- Heartbeats with the distributed manager to ensure that leaders are still up.
- Can be aware of hot spots and potentially split partitions into smaller partitions. (Consistent hashing would be useful here).
- Zookeeper, Redis (consensus deriving services).
- Didn’t talk about backups for fault tolerance.
- Could’ve discussed trade-offs for database technology decisions (b-tree vs. lsm-tree-and-sstable-index.)
high consistency design
- We can utilize both synchronous and asynchronous replication in a cluster, directing queries that require high consistency/low latency to their respective clusters.
- We can have a maximum latency cut-off for replicated followers, and not read from them if they’re too far behind, until they catch up.
follow-ups
- Research RAFT protocol for replication.
references
- https://www.youtube.com/watch?v=rnZmdmlR-2M
- Key-value store for availability - Crushing Tech Education
Footnotes
-
I would ask the interviewer what the expected use case for this application/key-value store is. If it is for a single system to use, we could continue with allowing the application to figure out how keep their own keys from conflicting. However, it’s for users anywhere to store a value in a global key-value store, we could use some unique user identifier appended to the user’s key. We could then partition by user locations or IP addresses. ↩