my solution
functional requirements
- Can retrieve a value given a key.
- Can insert/update a value at a given key.
- Bonus:
- Can manually invalidate keys.
- Can set TTL for cache keys.
non-functional requirements
- Highly available.
- Low latency.
- Highly scalable.
- High read/write ratio.
design process
Let’s first start with a naive solution, without scaling, and build up from there.
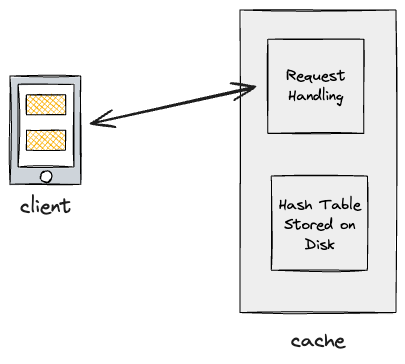
cache specifics
- The cache data is stored on memory on the cache machine, and data is served by a service on the machine that responds to requests.
- Requests will likely be TCP/UDP as all requests will be coming from trusted internal sources.
- External clients won’t be hitting the cache machines directly.
- The cache will be implemented with a simple hash map along with a doubly-linked list to allow for operations of setting and retrieving keys, as well as updating priorities.
- We need the doubly-linked list to implement eviction policies such as LRU, FIFO, etc.
- The type of eviction policy to use will be very dependent on the specific use case.
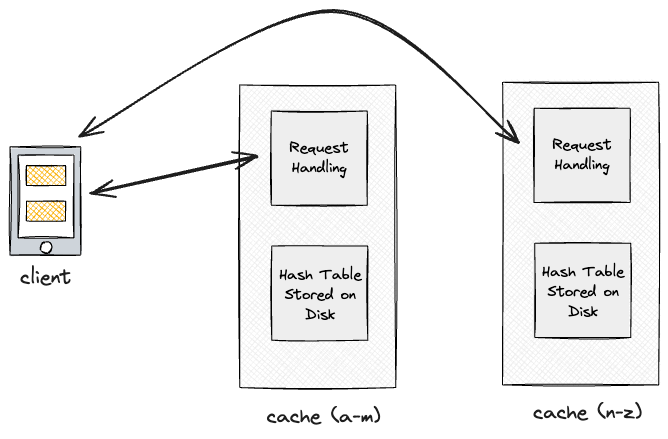
This simple approach reaches our functional requirements, but is neither scalable or highly available, due to the single point of failure. We have to address scaling from two angles: handling more requests and storing more data.
To store more data, we are bottlenecked by the size of the memory on a machine, and so sharding/partitioning is a solution.
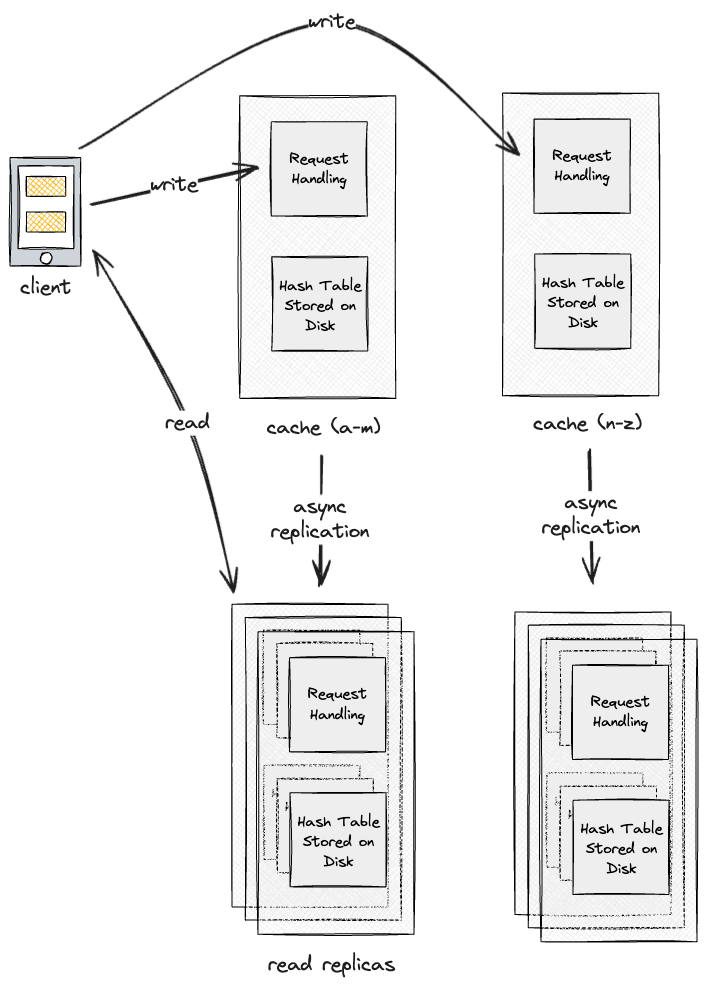
 Then, to increase the availability of each cache shard, we can asynchronously replicate the data in each shard using single-leader-replication to increase availability and read throughput.
Then, to increase the availability of each cache shard, we can asynchronously replicate the data in each shard using single-leader-replication to increase availability and read throughput.
We could theoretically use multi-leader-replication or leaderless-replicationas well, but assuming that the system is very heavily read-skewed, single-leader replication should be sufficient. With more writes, multiple leaders could be used, and things like quorums could be used to increase the likelihood of up-to-date values being returned.
dealing with hot nodes and failures
Partitioning by alphabetical key value is nice, but can easily lead to very uneven distribution of keys resulting in uneven handling of load and “hot nodes”.
To combat this, we can use a hashing function to more evenly spread out the keys. However, a normal hash function will jumble all hashed values if the number of nodes changes at any time (node failure, adding a new node, etc).
As such, we use consistent-hashing to hash our nodes on a ring.
setting manual ttl
We could allow key-value pairs to be saved with extra metadata, including a value of TTL (time-to-live), that is checked when any request is made for that key. If the data is past the TTL, then invalidate the value and request the updated value again from the database.
positive feedback
meta
- TODO: Research more on TCP/UDP and write out some notes.