Consistent hashing is a strategy to evenly distribute data between multiple partitioned systems (caching, databases, etc.), even in the face of faults.
how it works
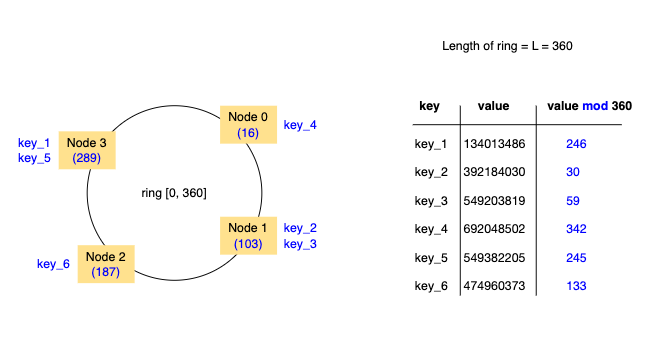
We start with a uniform hashing function like MD5.
All of the nodes of the distributed system are referenceable by some key like their IP address. This identifier is put through the hash function to place the node onto one of the predefined locations for nodes.
We then use the same hash function that is where is the length of the ring, to place data onto the ring. Data is stored on the first node in front of where it landed. This allows us to have even data distribution given that our hash function is uniform.
handling faults
On node failure, we only have to reassign values to the node in front of the one who failed, instead of repartitioning everything (which we would have to do with a static hashing strategy).
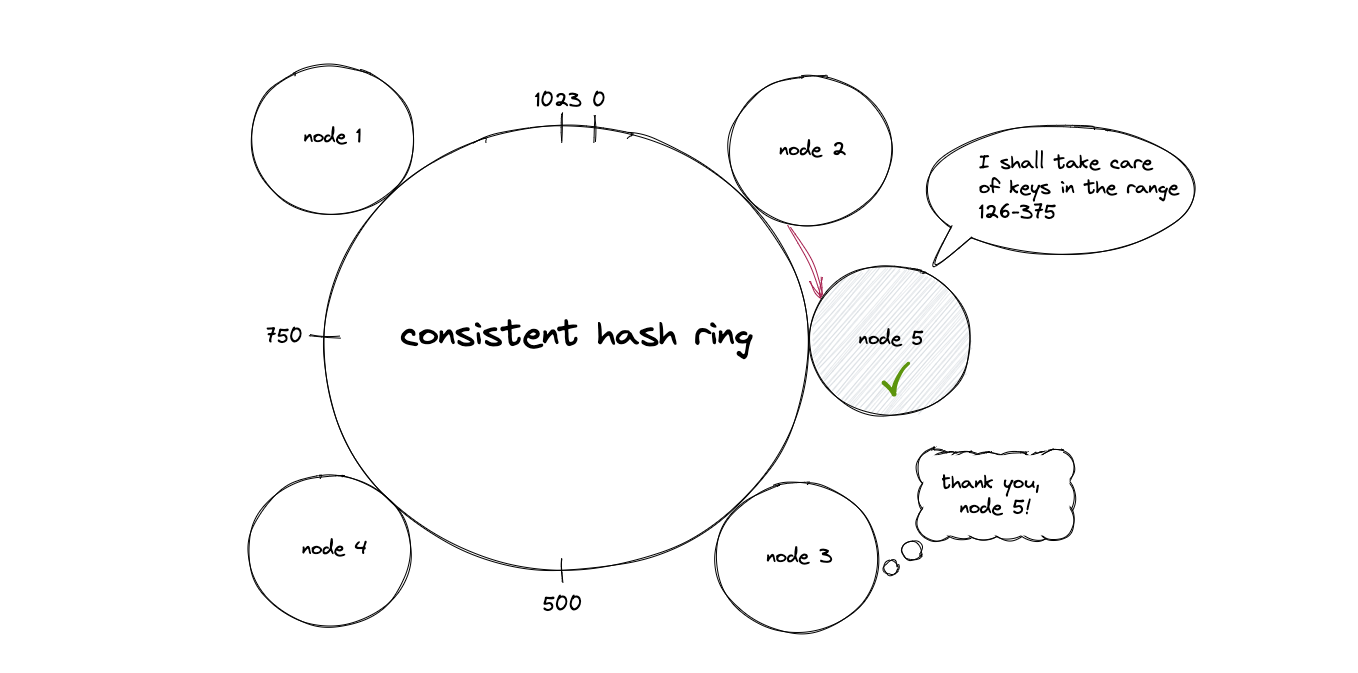
Note that nodes might start having uneven load because when a node is removed or goes offline, all of its load/data are moved to the next node, which can cause cascading failures.
This can be mitigated with virtual nodes. This is essentially the act of placing multiple “nodes” on the consistent hashing ring that all point to the same physical node. This way, we can spread out the load that a single physical node by spreading out “parts” of it interspersed on the ring.
dealing with hot spots
There is a variant of consistent hashing with bounded loads, that pre-delegates fallback nodes for each node in the ring, meaning that once the target node reaches a certain threshold, traffic will begin to be diverted to the designated fallback nodes.