Generally, we’ll need to partition our URLs because there’s way too many URLs not to. A lot of this problem is figuring out how to do this efficiently in the constraints of the operations we need to perform (fetching, deduplicating, graph traversal).
general partitioning
- We want to partition by
hostname. This will allow us to colocate frontiers, caching, and mirrors the general structure of web links, where a lot of links point back onto the same host.
deduplicating fetching
- Store visited URLs in a global shared cache that’s replicated for durability.
(+) Simple, don’t need to worry about consistency. (-) Requests might be slow if they are coming from multiple datacenters.
- Store them in local caches (per partition), and synchronize them asynchronously using version vectors. Conflicts can be resolved to just always take any partition as the source of truth when they say that a URL/webpage has been traversed/processed.
efficient dns/robots.txt lookups
- We probably want to cache DNS lookups, especially if we’re gonna be making a ton of requests to one host (i.e. Wikipedia).
- We don’t want to cache every DNS resolution on every partition. If we partition URLs by hostname, we can only cache, say
wikipedia.comon the partition that’s handling Wikipedia. - We can do similar partition/caching strategy for
robots.txtpolicies!
politeness/cooldown
-
Need to keep a datastore that stores when the last time we crawled a host was.
-
We shouldn’t wait in a blocking fashion, but we should put it back in the queue with a timeout (SQS has visibility timeouts).
https://www.youtube.com/watch?v=MdWvMX4J-Vc
archive
- typical usecases.
- search engine indexing.
- web archiving.
- data mining the internet for training data for machine learning models.
- clarifications.
- needs to recursively go to webpages, download them, and continue exploring the links on those pages.
- in this case, assume it is for search engine indexing.
- web crawler indexes one billion pages in a month.
- only scrapes for html files.
- needs to consider newly created pages.
- needs to store these indexed pages for five years.
- pages with duplicate content should be ignored.
- back of the envelope estimations.
- needs to download about 400 pages per second.
- peak would be about 800 pages per second.
- assuming the average html webpage is 500 kilobytes, we need to store 500 terabytes per month and storage of up to 30 petabytes for 5 years.
- needs to download about 400 pages per second.
- design.
- we first assemble some seed urls for our web crawler to start at.
- starting at these urls, the web crawler calls a dns server to convert the urls into ip addresses.
- we need a component that actually parses the content in the webpages and extract new urls to visit.
- should be run separately because it will slow down the crawler.
- we can use a message-queue and asynchronism to process new webpages without slowing down the actual web crawler.
- because the number of pages in the queue can grow very large, we should keep a buffer for fast lookup of urls while keeping the majority of the urls on disk.
- we can keep track of webpages that we’ve already seen with a sort of set structure, where we compare the hashes of two html files to see if we’ve seen it before.
- should have another microservice that extracts urls from an html file, which can also run asynchronously.
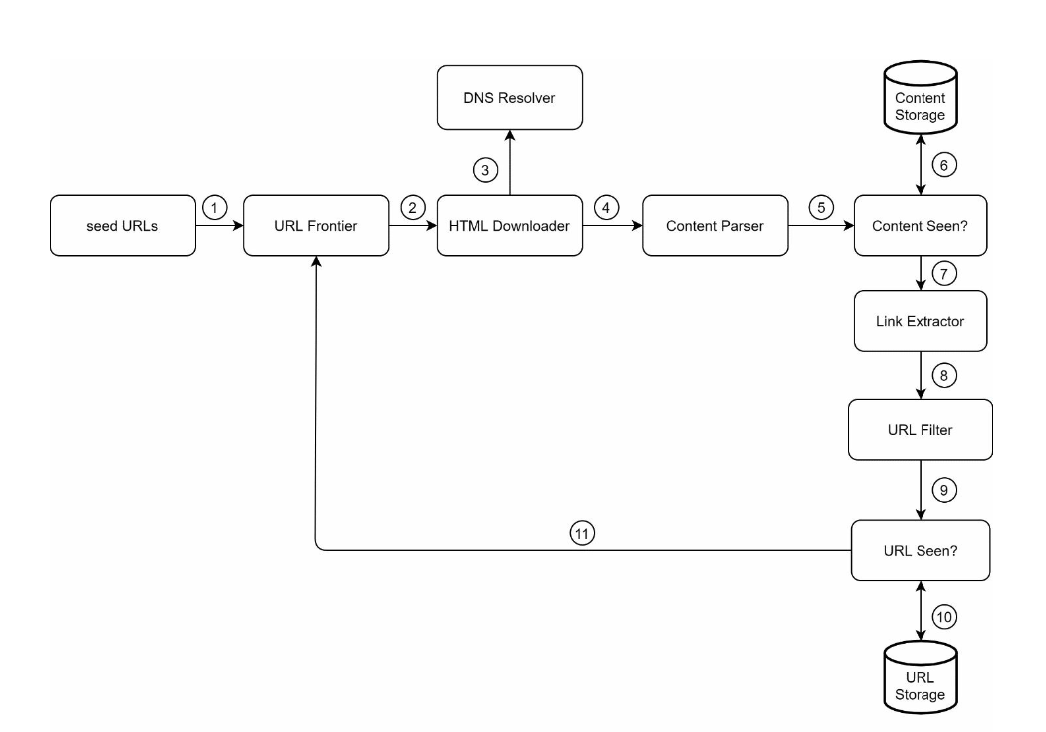
- politeness is a concept important in the field of web crawlers because we don’t want to be ddos’ing any hosts.
- we should spread out different hostnames to different workers in our distributed system so that we don’t have all of our workers hit the same hostname in parallel.
- we can cache
robots.txtfiles for websites.- this is a file websites put up to tell web crawlers what they should and should not index.
- further points.
- many websites do server-side rendering or dynamic content.
- how do we deal with this?
- many websites do server-side rendering or dynamic content.