notes
-
Google File System was designed in 2003 to support a highly available, eventually consistent file storage system that stored relative large files (hundreds of MB to GBs).
-
Features:
- Supports appending of data to large files; writes do not go back to edit previously written data.
- Supports atomic append operations, as many consumers may be concurrently appending to a single file.
- Prioritizes continued high bandwidth/throughput instead of low latency on individual requests.
-
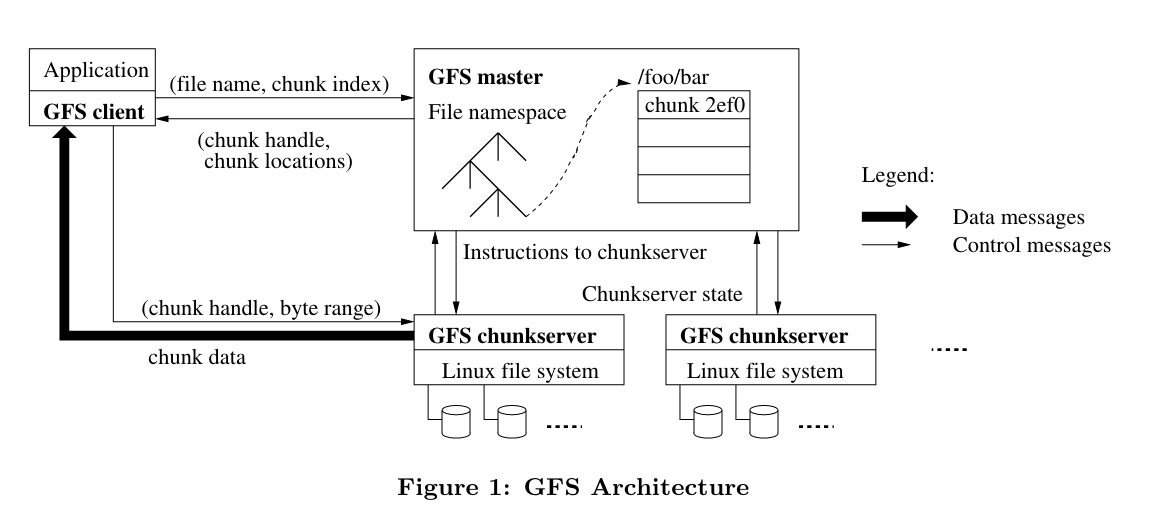
Architecture:
- Files are split into chunks of 64MB, which are then replicated and spread out to distributed chunkservers, which store these files on their file systems.
- A master node keeps track of file metadata (in memory), as well as a mapping of which replicas have which chunk.
- This is done in-memory because it eliminates the need to keep persistent storage on the master node in sync with reality. It just grabs the current state when it comes online, and then because every other positioning/replication decision goes through it, the information should be correct.
- All read and write requests first go through the master, and then the client thereafter calls the chunkserver directly.
-
Fault tolerance:
- An operation log, which tracks all metadata changes, such as file versions and chunk mappings, is used by the master for durability.
- This log is persisted locally and remotely to allow master to pick back up after going down.
- Backups are also created periodically. The log only needs to store logs from the time of the most recent backup.
highlights