my solution
overview
Design a booking and reservation system for a parking garage.
scale estimates
- In a level of a parking garage, 200 parking spots.
- 10 levels per parking garage, so 2000 spots per garage.
- 100 parking garages across the US, so 200,000 parking spots being managed.
- Average parking garage booking is 2 hours long, 8-10 bookings per spot per day.
- ~1,000,000 bookings per day.
functional requirements
- Users should be able to reserve a time slot in the parking garage.
- Users should be able to specify specific requirements such as an extra-large vehicle, or an electric vehicle.
- Users should be able to cancel a reservation.
- Users should be able to pay for a reservation, see their reservations.
non-functional requirements
- Consistency.
- A user who pays for a reservation shouldn’t have their reservation overwritten by a later request due to concurrency issues.
- High availability.
api design
findAvailableTimeslots(start, end, location, specialRequirements)bookTimeslot(start, end, spotId)
data modeling
| Model | Fields |
|---|---|
reservations | id, start, end, parking_spot_id, user_id |
payments | id, payment_method_details |
parking_spot | id, is_large, is_electric, is_accessible |
parking_garage | id, address |
user | id, name … |
For finding available slots within a given timeslot [s,e], we can do something like this:
SELECT UNIQUE(*) FROM parking_spot ps
JOIN reservations r ON r.parking_spot_id = ps.id
WHERE r.start >= e or s <= r.end
GROUP BY ps.idHopefully something like a b-tree index on the time columns of reservations would enable us to have better-than-linear runtimes for those range-based queries.
high-level design
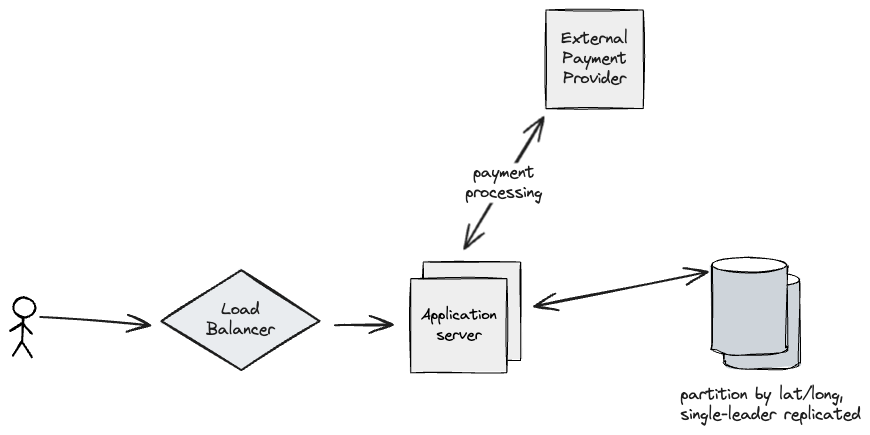
specifics
- How to handle when two users book at the same time and the system tries to book the same slot?
- Could set up some application logic to retry queries times, to try to automatically book a different available slot.
- How to handle storing large volumes of reservation data?
- We can geographically partition our database nodes, as someone on the west coast likely isn’t trying to book anything to do with parking on the east coast.
- This allows us to ease the data/traffic load on all our database nodes, while allowing us to use single-leader replication per-partition to improve system durability.
- We can geographically partition our database nodes, as someone on the west coast likely isn’t trying to book anything to do with parking on the east coast.
positive feedback
- Noting that we want strong consistency and availability at the expense of latency was good.
- Partitioning geographically by location of parking garages was good.
- Most of the data modelling was on-point, except for a couple of missing fields.
- Talking about scale was good, and how it’s not necessarily a massive data-intensive problem.
critique
general
- Questions I could have asked:
- How many levels are there? How many buildings?
- Are there free/paid spots?
- Should clarify about what specific problem we’re looking for!
- API design? System design? OOP design?
- Didn’t talk explicitly about the trade-offs between having strong/causal consistency and having higher latency.
api design
- Could have dove a bit more into specific API calls that would be required.
- Cancelling a reservation.
- Changing a reservation.
database
- Missed the storing of rates in the
parking_garagetable. - Could’ve discussed the trade-offs of using boolean variables vs. an enum in the
parking_spottable.