my solution
Let’s assume that this is a leaderboard for a very popular online video game with 100,000 DAU, 1M MAU.
functional requirements
- See the players at the top of the leaderboard.
- Potentially allow filtering by region.
- See leaderboard for friends.
- See position of user in leaderboard as well as surrounding players.
- Leaderboard should update with new scores that are set by players.
non-functional requirements
- Read-your-writes consistency - a user should see their updated score on the leaderboard after they achieve it.
- It’s fine to just have basic eventual consistency for other users’ scores.
- Higher write volumes, but read latency should be lower.
- More people will be playing the game/setting scores vs. just perusing the leaderboard.
- Durability, consistency.
- A skewed number of read requests will be for the top 10/top 100 of the leaderboard.
back-of-napkin estimates
- 100,000 DAU, but only a smaller percentage of these players achieve scores that beat their best.
- Let’s say 20%, or 20,000 daily writes are needed to update the database.
high-level api requirements
- User can query for top players/scores in the leaderboard.
GET /leaderboard?limit=50&offset=0- User can query leaderboard with just friends.
GET /leaderboard?filter=[list_of_friends]- Query for their own high score in the leaderboard, and see surrounding scores.
GET /leaderboard?user=[user_id]- Update the best score for a user when they achieve it.
PUT, POST /leaderboard/:user_idhigh-level data modelling
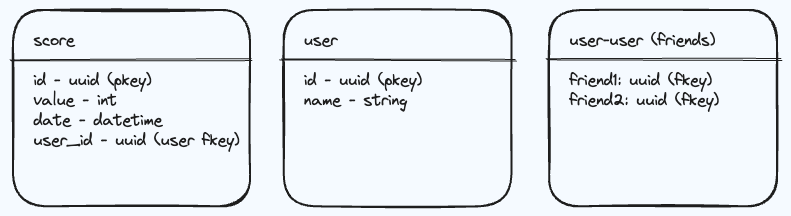
- For the sake of the problem, we only need to store users and scores.
- An extension could be to have a join table to store friend relationships.
high-level architecture
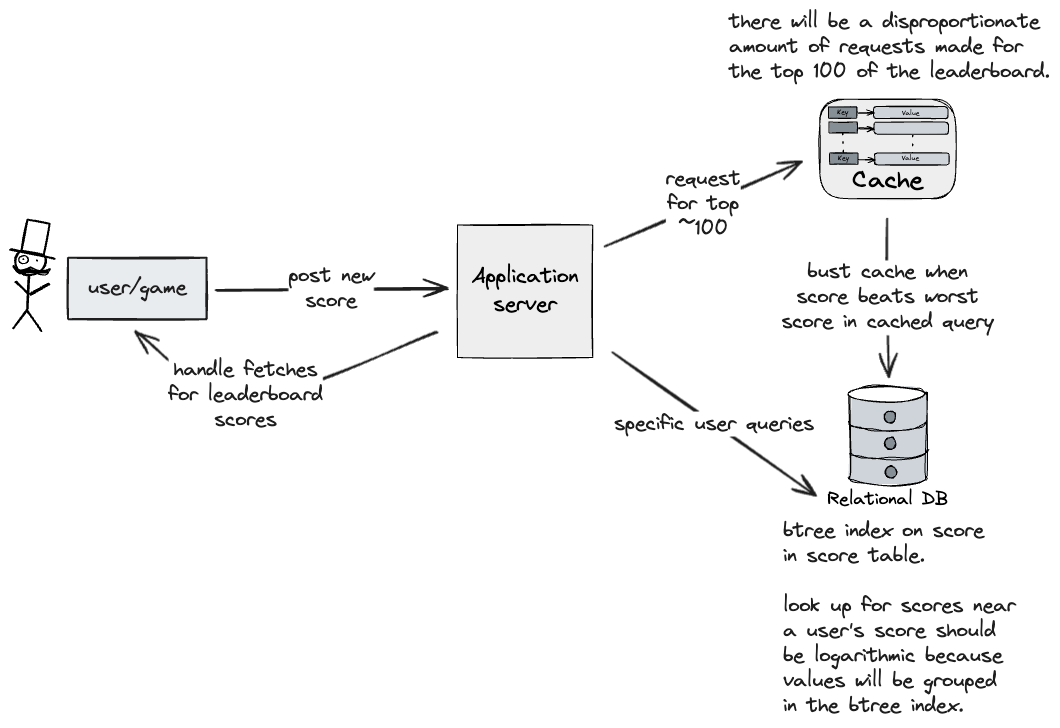
- Standard game and server set up, but I made some changes to achieve our functional requirements with some more efficiency.
- Cache for ”hot” queries.
- Common queries, like top 100 scores in the world, will be accessed a lot, so instead of requiring a DB call for each of them, we can cache the result of that query, and update the cache when a new score arrives that beats a score in the old query.
- We can create a btree index on the scores table, so that “range queries” for scores near a user’s score will like close-by in the index.
- meta: is this even how btree indexes work with range queries?
- answer: yes it is.
deep dive into caching

- The cache will store the results of frequently made queries like the top 100 in the leaderboard.
- We can make use of stream processing such as using a change data capture to have the cache subscribe to writes on the database, and update necessary cached queries when a new score would change the result of that query.
how to scale 10x?
- We could replicate the database, dealer’s choice of single-leader or multi-leader replication, depending on scale, if we have multiple datacenters.
- We would need to have some sort of causal consistency in-place to ensure that users could see their new scores in the leaderboard (and maybe their friends as well). Eventual consistency for everyone else’s scores would be fine.
positive feedback
- Caching frequently used queries was a good idea.
critique
general / requirements
- I didn’t really understand the problem as it’s normally described, and probably could have focused more on aggregation of singular events to create a “top k” leaderboard instead of just individual game scores.
- Didn’t consider the possibility/requirement of fetching high scores within a time window.
design
- For this problem, it was better to build up from a base knowledge of data structures/algorithms, such as top k elements/min-heap.
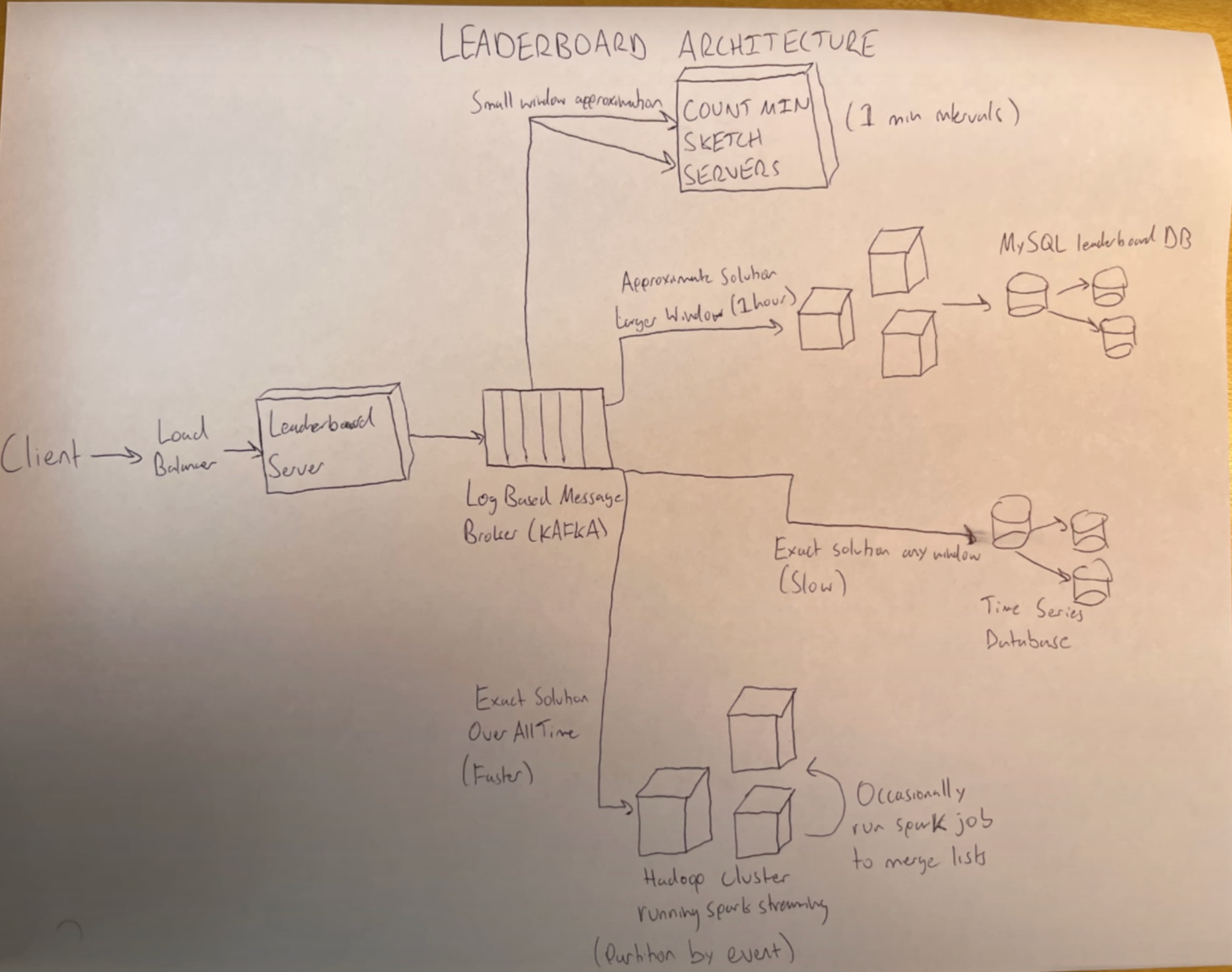
- The image shows four possible solutions on the right, each with similar ingestion pipelines on the left.