my solution
functional requirements
- Jobs can be created to run at specific times or intervals.
- Jobs can be given a priority value.
- Jobs can be updated or deleted.
- Jobs can run concurrently and asynchronously.
- We should be able to query for the status of a job.
non-functional requirements
- Scalable, should be able to scale to manage many concurrent jobs.
- Availability over consistency.
- We want availability, but also should have exactly-once guarantees, in case jobs have side effects.
- If we inform the client that we don’t have exactly-once semantics, and instead have something like at-least-once, then we can have distributed computation with possible duplicates.
- Durability, jobs shouldn’t be lost due to system failures.
- BONUS: Should have some sort of guarantee in terms of margin of error of scheduled time compared to actual run time of job.
api design
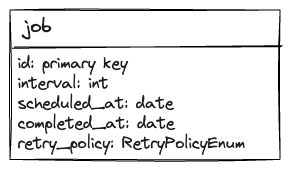
createJob(interval: Optional[int], scheduled: Optional[Date]) -> jobIdgetJobById(id: string)deleteJobById(id: string)updateJobById(id: string, values)getRunningJobs()
database design
design process
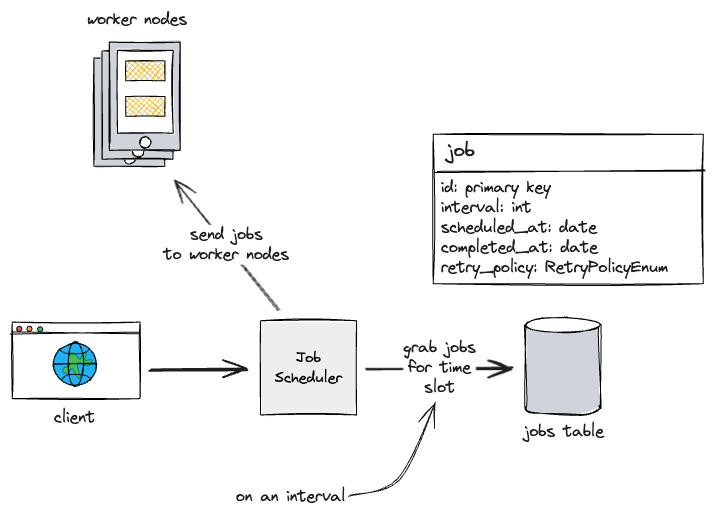
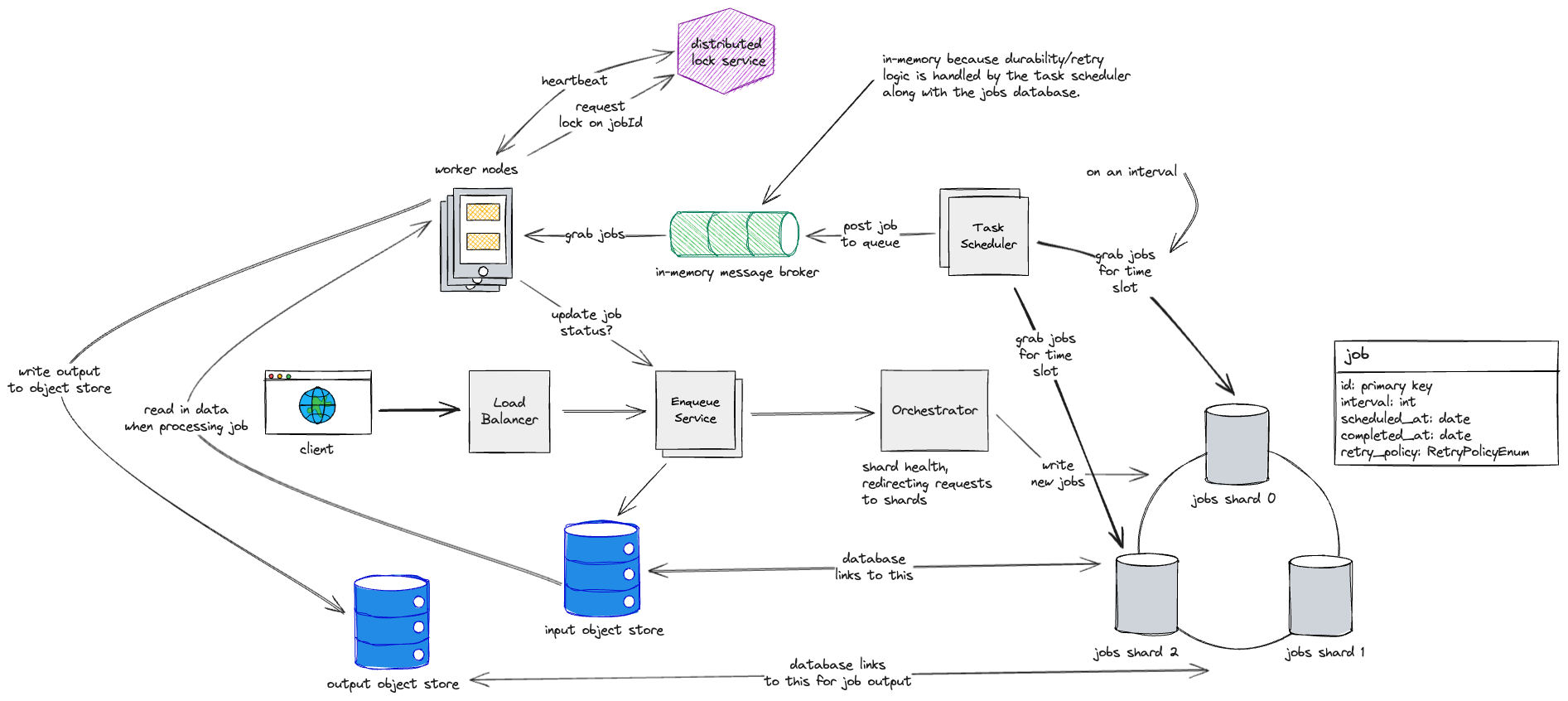
We have a service called the job scheduler that handles running queries to the DB at some set interval, based on how high granularity we want to provide to users (per hour, per minute, etc).
Query specifics
For one-time scheduled jobs, we’ll filter in our query for jobs that are not yet completed and who’s scheduled time lies within the current query’s time window.
For recurring interval jobs, we will calculate the next run date/time with the previous
completed_attime and the interval specified for the job, and see if it falls wtihin the current query’s time bounds.
Then, from all the jobs that need to be run we’ll send the jobs (this could be a reference to another database/service that specifies what to actually do for a job ID, or could be something lightweight like code that can be passed from the scheduler to the worker node).
Some issues with this approach:
- Many single points of failure, including database, job scheduler.
- Job scheduler will have to wait if there are no worker nodes available, so there is a lower availability for clients to submit new requests.
- Job scheduler service is responsible for handling all requests to add/delete/update jobs, while also running process on an interval to query for jobs that need to be run and sending them to worker nodes.
First, let’s solve that last issue by separating our monolithic service into two services. One that handles updates to the DB, and one that is solely responsible for finding jobs that need to be run and sending them to worker nodes. Let’s call them the job servicer and the task scheduler, respsectively.
Also, we’ll horizontally scale the job servicers based on demand, and place a load balancer in front of them.
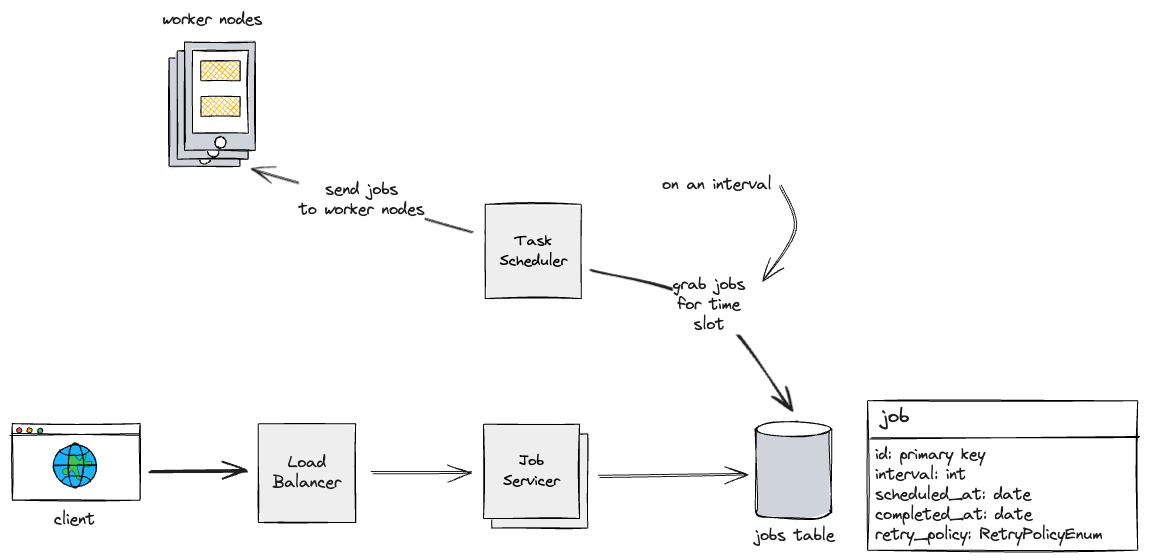
Now that we have potentially many applications sending requests to our database, we should increase it’s throughput by sharding the data so that we can split out read/write requests between jobs.
We can shard the data on a consistent hashing ring based on a unique job ID, likely based on some unique identifiers such as the user ID, creation time, etc.
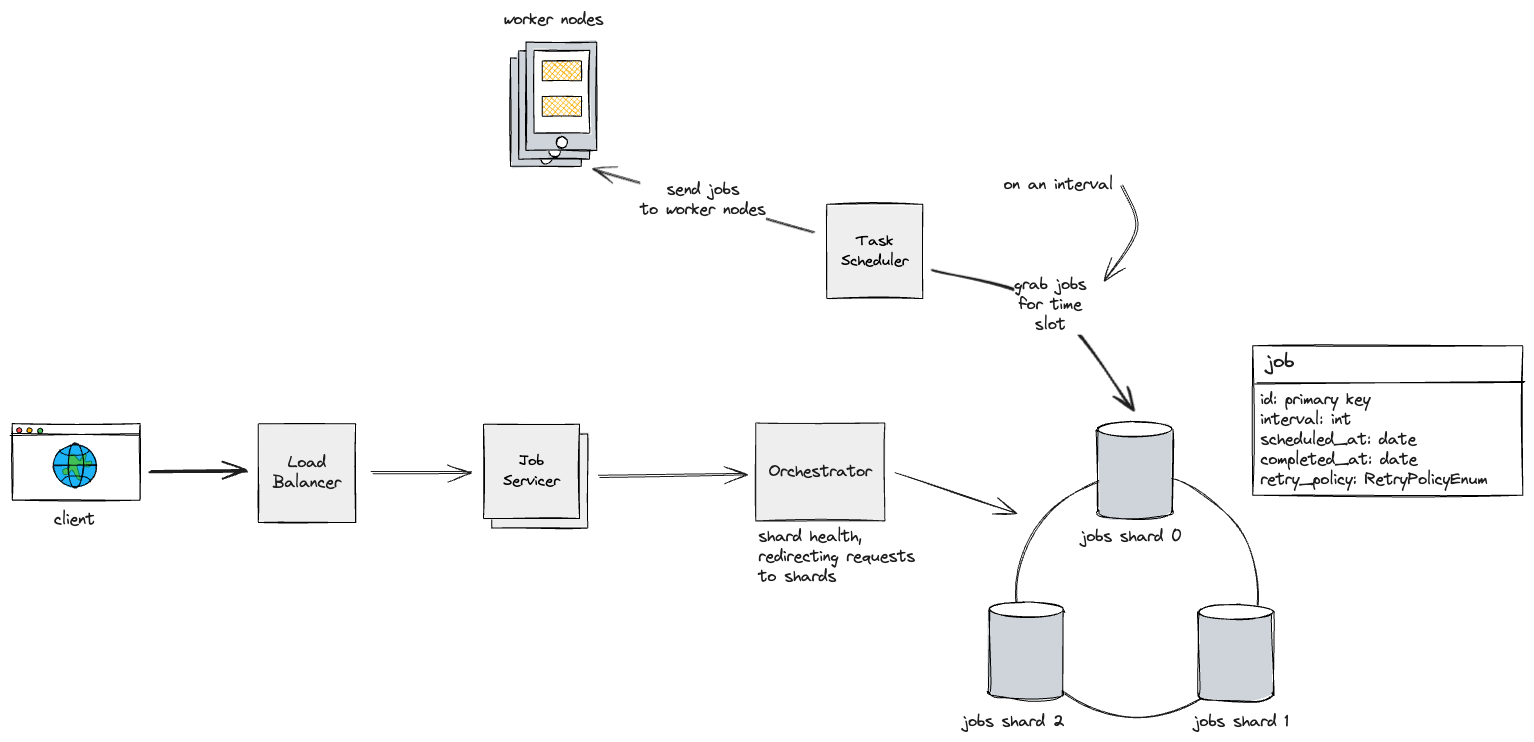
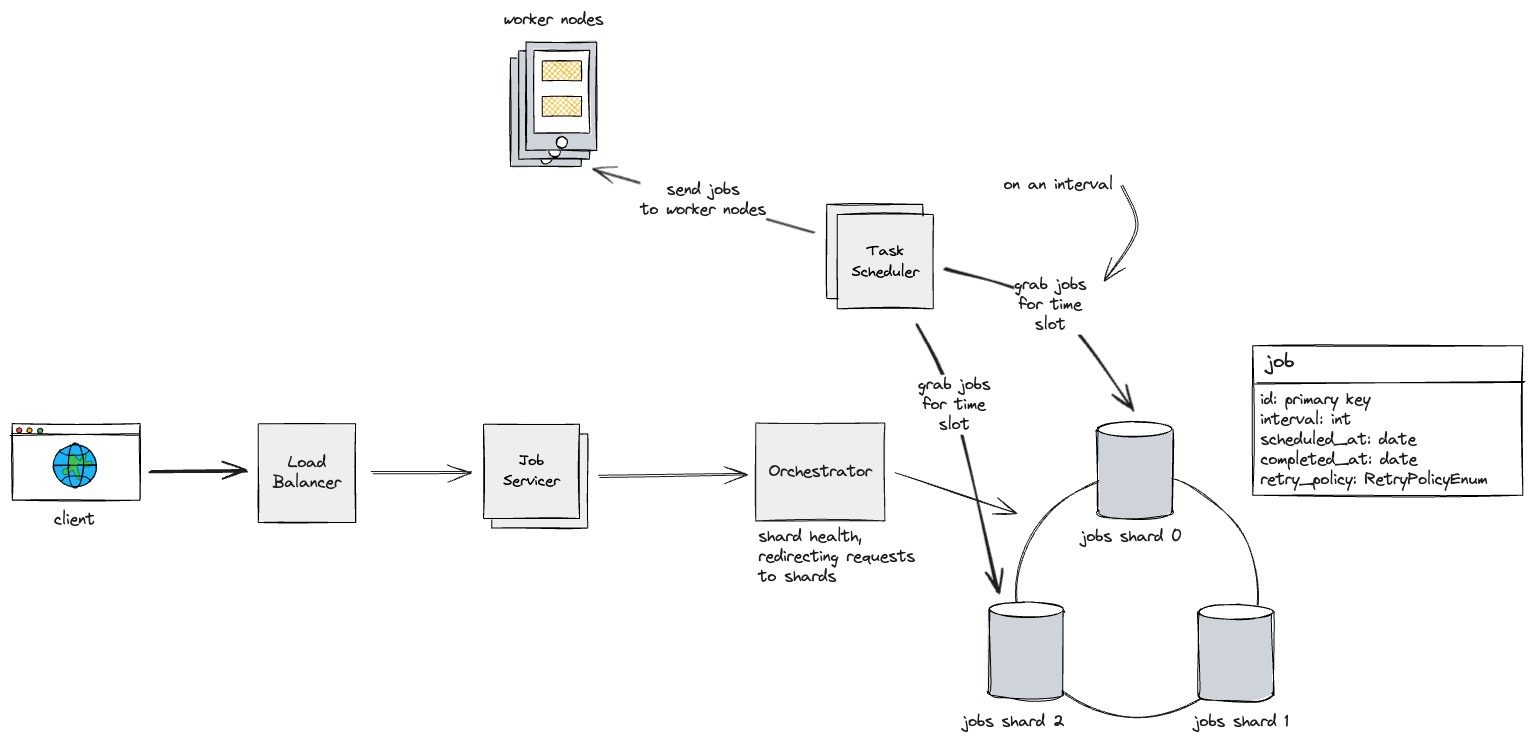
Now, our task scheduler needs to run queries against each shard, so we could have separate instances of our task scheduler that handles each shard (these could be in different datacenters).
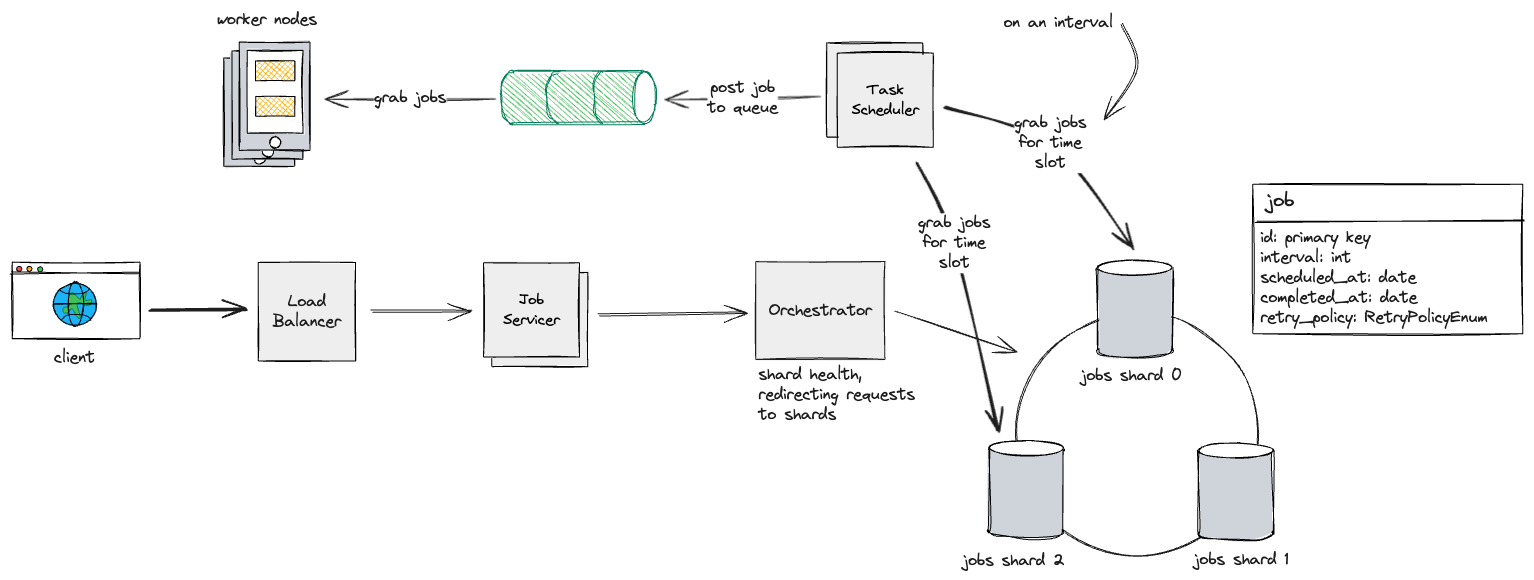
Finally, we will need to decouple sending of jobs from the actual worker nodes. For this, we use a log-based queue that our worker nodes can subscribe to. We use a log-based queue so we have durability in case of a fault in our message broker.
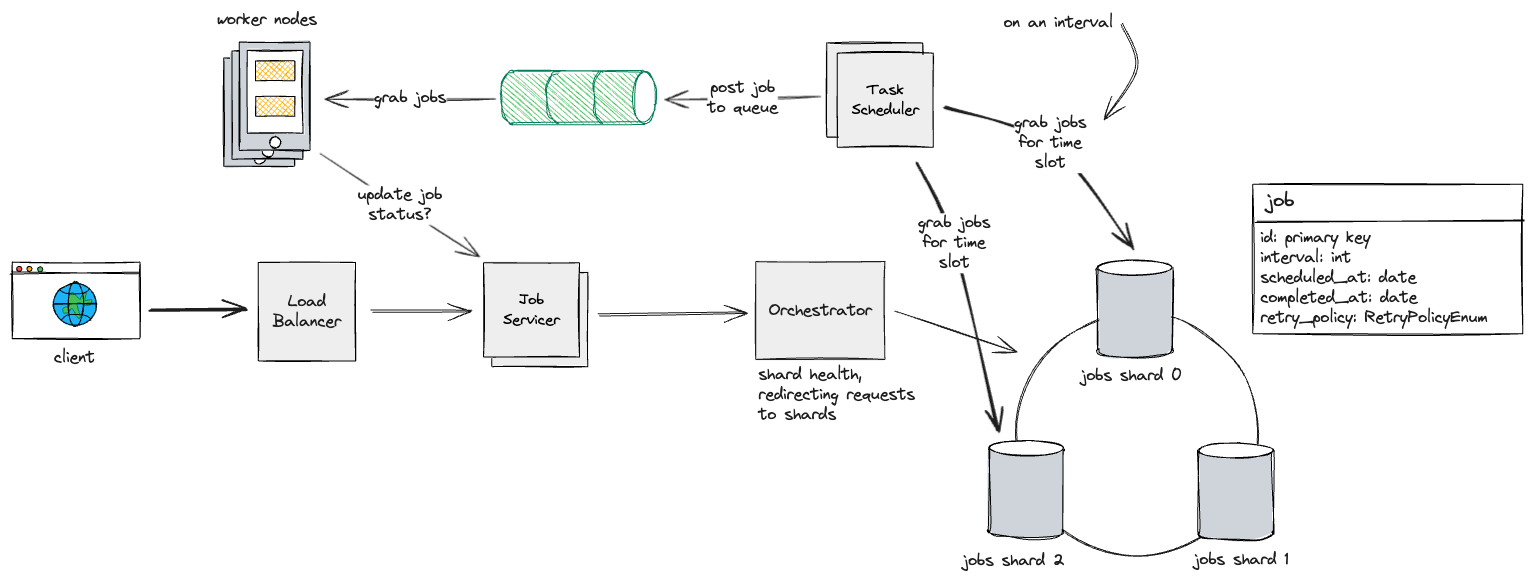
Then, we can have the worker nodes send a request to the job servicer/orchestrator to update the status of the job in the database.
considerations
- SQL vs. NoSQL.
- Prefer NoSQL.
- We only have one table, and the various values in the
jobstable are not dependent on each other at all. This means that a document style database will allow for less overhead for us to save these values.- Many NoSQL databases still provide good functionality for filtering by certain fields/values.
- How do the worker nodes notify the job scheduler that the job is successfully completed? How do we update complete status in the DB?
- Naively, we can have the worker nodes send a request (RPC, TCP/UDP) to our orchestrator in order to have it forward a request to update the database in the correct shard.
- What do we store on the message queue? Just a job ID? Or enough data for the worker to run the job?
- If we store just a job ID:
- We need to grab job data from the database from the worker node before running a job, which adds another round trip through our internal networks.
- If we store enough metadata to run a job.
- One less round trip, but we need a lot more storage on our message broker.
- If we store just a job ID:
positive feedback
critique
general
- Didn’t realize that jobs should have an output file and not just a status!
- This informs the design, as we likely need input and output data/blob storage to store compiled binary code that the workers can run, as well as the output of those programs.
- Could have talked about having an index on the database based on timestamp, to improve query times, but not too important as it’s likely not the bottleneck.
- Didn’t talk about how to detect failed jobs/timed out jobs.
- Because I didn’t talk about retries, I didn’t end up talking about how to handle the possibility that a single job is run more than once due to concurrency.
- We could have a distributed lock service that workers need to communicate with in order to ensure that they have a lock on the specific job ID.
- Because I didn’t talk about retries, I didn’t end up talking about how to handle the possibility that a single job is run more than once due to concurrency.
- An in-memory message broker is actually better for this system compared to log-based, because we don’t need the durability in the case that we’re storing these values in a separate database anyways.
api design
createJob(code: binary, schedule: scheduleString)
back-of-envelope estimations
- Jobs per second.
- How long does a job take?
- Storage needed.
- How much storage per job?
todo
- Research distributed locks, Zookeeper.